Agentic coding has quickly scaled from promising demos to a force that is reshaping how software is developed and how frontier AI systems are built and deployed. Systems like Claude Code, Codex, and Cursor have gained massive user adoption and now generate an extraordinary volume of tokens. To meet this growth, data centers requiring tens of gigawatts of power are being built, backed by hundreds of billions of dollars in investment.
At this scale, the efficiency of the systems orchestrating model inference becomes critically important. Even small improvements in throughput per GPU, when applied across a production fleet, can translate into substantial capacity savings while serving ever-growing demand.
TokenSpeed Overview
TokenSpeed is designed from first principles for the agentic-inference regime. It delivers speed-of-light inference for agentic workloads, with a compiler-backed modeling mechanism for parallelism, a high performance scheduler, a safe KV resource reuse restriction, a pluggable layered kernel system that supports heterogeneous accelerators, and SMG integration for a low-overhead CPU-side request entrypoint.
The modeling layer adopts a local SPMD (Single Program, Multiple Data) design that balances performance and usability. TokenSpeed enables developers to specify I/O placement annotations at module boundaries. A lightweight static compiler then automatically generates the required collective operations during model construction, eliminating the need to manually implement communication logic.
The TokenSpeed scheduler decouples the control plane from the execution plane. The control plane is implemented in C++ as a finite-state machine that works with the type system to enforce safe resource management, including KV cache state transfer and usage, at compile time rather than at runtime. Request lifecycle, KV cache resources, and overlap timing are represented through explicit FSM transitions and ownership semantics, so correctness is enforced by a verifiable control system rather than convention. The execution plane is implemented in Python to maintain development efficiency, enabling faster feature iteration and lower cognitive load for researchers and engineers.
The TokenSpeed kernel layer separates kernels from the core engine and treats them as a first-class modular subsystem. It provides a portable public API, a centralized registry and selection model, organized implementations, an extensible plugin mechanism for heterogeneous accelerators, curated dependencies, and unified infrastructure for rapid iteration. We have also invested heavily in performance optimization on NVIDIA Blackwell — for example, we built one of the fastest MLA (Multi-head Latent Attention) kernels for agentic workloads. In the decode kernel, we grouped q_seqlen and num_heads to fully utilize Tensor Cores as num_heads are small in some of these use cases. The binary prefill kernel includes a fine-tuned softmax implementation. TokenSpeed MLA has been adopted by vLLM.
Performance Preview
Today, we are sharing a performance preview of TokenSpeed. Development began in mid-March 2026. The engine and kernels remain under active development, with production hardening planned over the next month. Many additional PRs are expected to land in the coming weeks.
Coding agents present unusually demanding inference workloads. Contexts routinely exceed 50K tokens, and conversations often span dozens of turns. Most public benchmarks do not fully capture this behavior. Together with the EvalScope team, we evaluate TokenSpeed against SWE-smith traces, which closely mirror production coding-agent traffic. Because generation speed is crucial to the user experience for agents, our objective is to maximize per-GPU TPM (tokens per minute) while maintaining a per-user TPS (tokens per second) floor — typically 70 TPS, and sometimes 200 TPS or higher.
We benchmarked our design against TensorRT-LLM — the current state of the art on NVIDIA Blackwell — and diverged from its approach wherever we believe better trade-offs exist for agentic workloads.
Note: This blog focuses on single (non-disaggregated) deployment. PD disaggregation support is undergoing cleanup, and we will cover it in a dedicated follow-up blog.
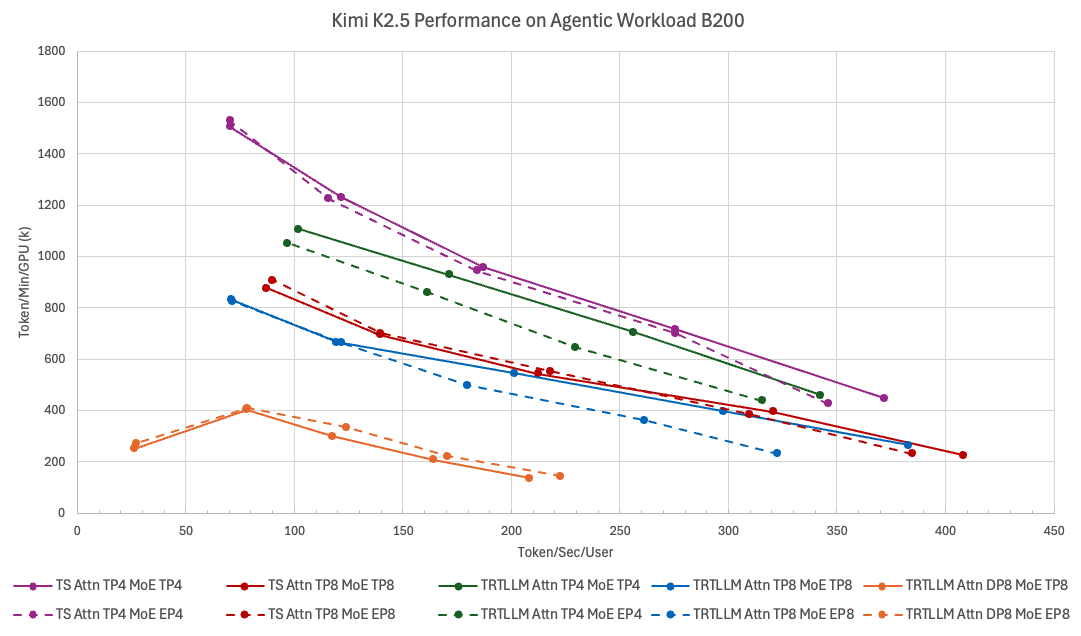
The figure below shows the Kimi K2.5 performance Pareto curves of TokenSpeed and TensorRT-LLM across different deployment configurations (without PD disaggregation). Each curve uses TPS/User (x-axis) as the latency metric and TPM/GPU (y-axis) as the throughput metric, and is traced by sweeping concurrency. For coding agents (above 70 TPS/User), the best configuration is Attention TP4 + MoE TP4, where TokenSpeed dominates TensorRT-LLM across the entire Pareto frontier: roughly 9% faster in the min-latency case (batch size 1), and roughly 11% higher throughput around 100 TPS/User.
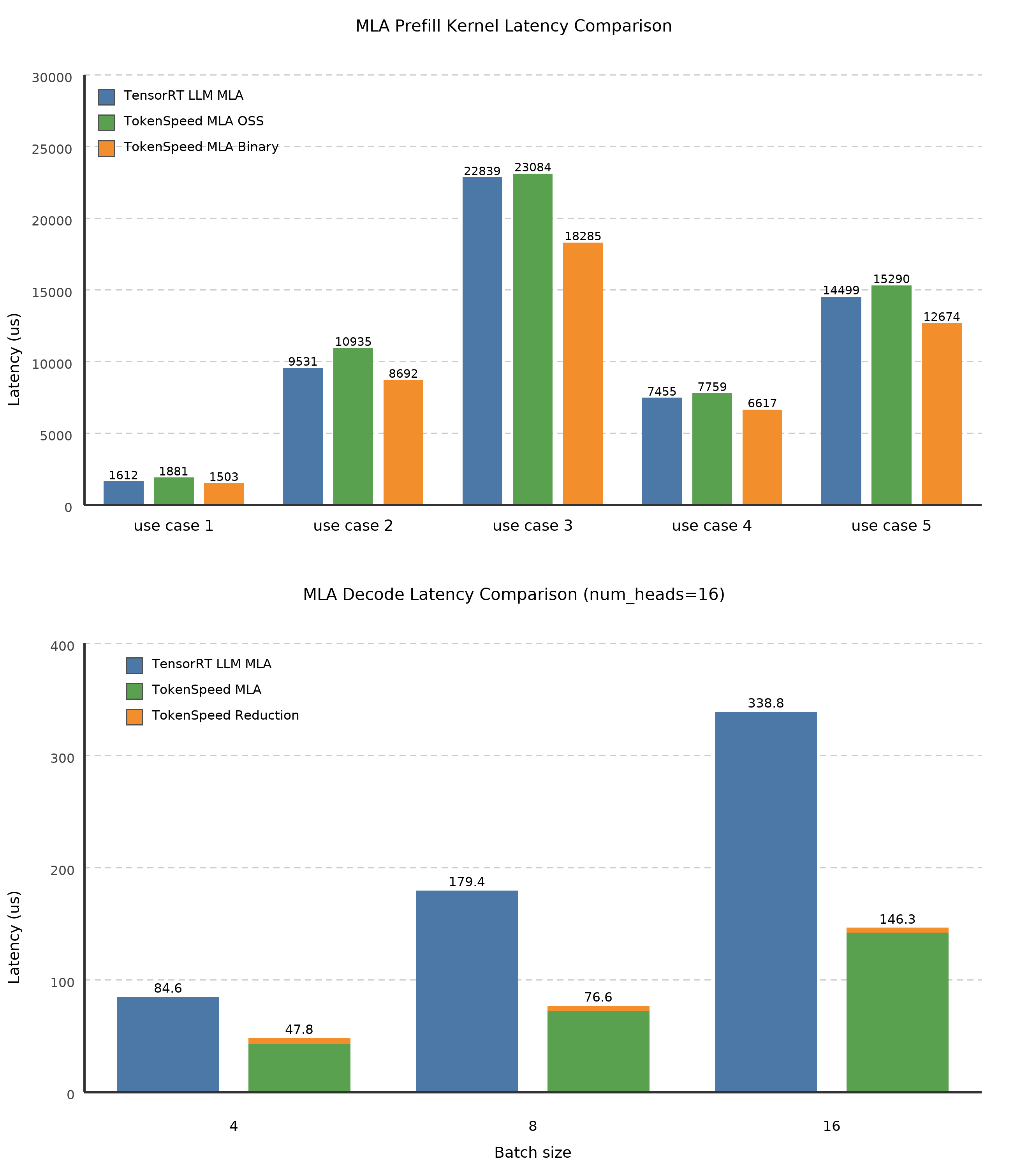
One of our core optimizations is TokenSpeed MLA. The figure below compares TokenSpeed MLA against TensorRT-LLM's MLA, the current SoTA on NVIDIA Blackwell. Our optimized binary-version prefill kernel uses NVIDIA-internal knobs to fine-tune the softmax implementation, outperforming TensorRT-LLM's MLA across all five typical prefill workloads for coding agents (prefill with long prefix KV cache). The decode kernel folds the query-sequence axis into the head axis to better fill the BMM1 M tile, improving Tensor Core utilization. Combined with other optimizations, this nearly halves latency relative to TensorRT-LLM on typical decode workloads with speculative decoding (batch sizes 4, 8, and 16 with long prefix KV cache).
Acknowledgments
TokenSpeed is developed in collaboration with NVIDIA DevTech, AMD Triton, Qwen Inference, Together AI, Mooncake, LongCat, FluentLLM, EvalScope, NVIDIA Dynamo, and the LightSeek Foundation.[1]
We are grateful to the TensorRT-LLM maintainers, whose work set the bar we measured ourselves against. Many of our optimizations were inspired by TensorRT-LLM, including the one-CUDA-graph optimization and forward pass optimizations. We are also grateful to the broader open-source inference community — including Triton, FluentLLM, vLLM, EvalScope, FlashInfer, SGLang, and others — for raising the ceiling on what production LLM serving can look like. Parts of the TokenSpeed runtime reflect upstream lineage from FluentLLM, alongside substantial original work in the scheduler, modeling layer, kernel stack, and TokenSpeed MLA, with the overall system optimized for speed-of-light agentic inference.
We acknowledge and appreciate the compute support from OpenAI, NVIDIA, AMD, Verda, and Nebius.
Contributors
Co-creators. Enwei Zhu, Jiying Dong, Xipeng Li (NVIDIA) · Pengzhan Zhao, Kyle Wang, Lei Zhang (AMD) · Jiandong Jiang, Tuan Zhang, Minmin Sun (Qwen Inference) · Jue Wang, Yineng Zhang (Together AI) · Hongtao Chen, Mingxing Zhang (Mooncake) · Bo Wang, Fengcun Li (LongCat) · Xiangyang Ji, Yulei Qian (FluentLLM).
Core runtime. Scheduler — Yulei Qian, Fengcun Li, Bo Wang. Kernels — Lei Zhang, Pengzhan Zhao, Kyle Wang. Modeling — Yulei Qian, Xiangyang Ji, Jue Wang. MLA — Albert Di, Jiying Dong. Grammar and sampling — Jue Wang, Weicong Wu. MoE — Hongtao Chen. VLM — Hongtao Chen, Fengcun Li, Bo Wang.
Model optimization. Kimi K2.5 speed-of-light optimization — Enwei Zhu, Jiying Dong, Yue Weng, Albert Di. Qwen 3.6 — Minmin Sun, Tuan Zhang, Jiandong Jiang. DeepSeek V4 — Jiying Dong, Qingquan Song, Qiukai Chen, Yechan Kim, Hejian Sang. GPT-OSS on AMD — Pengzhan Zhao, Kyle Wang. Minimax M2.7 — Fan Yin, Jue Wang.
System and integration. Distributed runtime — Xuchun Shang, Teng Ma. Speculative decoding — Yue Weng. AsyncLLM and SMG — Simo Lin, Keyang Ru, Xipeng Guan. TensorRT-LLM kernels — Aaron Liu, Enwei Zhu. Metrics — Fred Wang. EvalScope benchmark — Xingjun Wang, Yunlin Mao. Dynamo integration — Yuewei Na, William Arnold. ↩︎